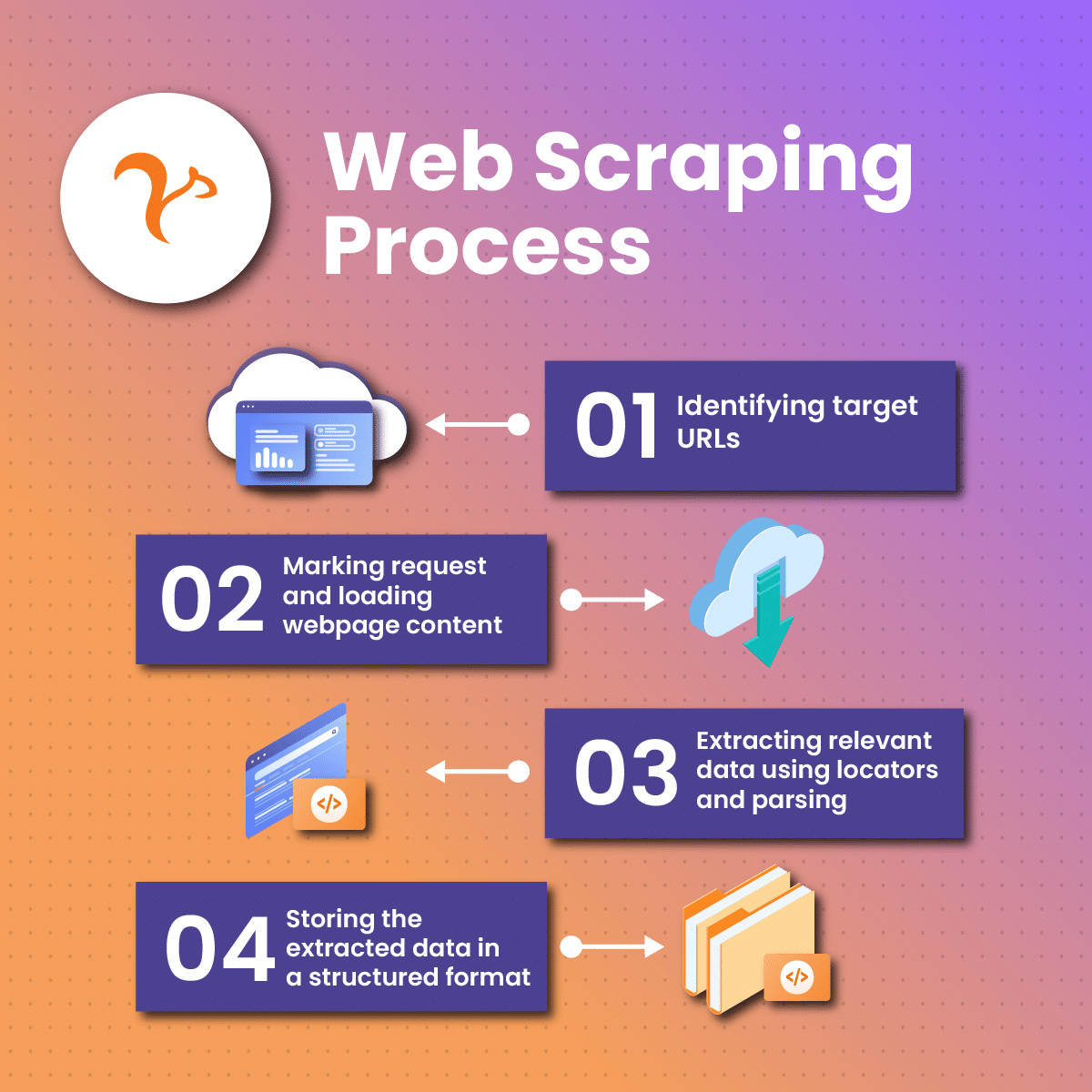
Web scraping, internetten veri çekme yöntemleri arasında oldukça etkili bir tekniktir. Kullanıcılar, web sitelerinden bilgileri toplamak için Beautiful Soup ve Scrapy gibi kütüphanelerden yararlanarak analiz veya saklama amacıyla ihtiyaç duydukları verileri elde edebilirler. Bu yazıda, web scraping tekniklerinin nasıl çalıştığını, bu süreçte kullanabileceğiniz araçları detaylı bir şekilde inceleyeceğiz. Ayrıca, web scraping’in etik hususları ve yasal sınırları olduğuna da değineceğiz; böylece doğru bir yöntemle hedeflediğiniz verilere ulaşabilirsiniz. Web scraping sayesinde, dijital dünyadaki verileri sistematik ve verimli bir şekilde analiz edebilirsiniz.
Web sayfalarından otomatik olarak veri çekme işlemi, çeşitli araç ve tekniklerle gerçekleştirilen bir süreçtir. Veri toplama sürecinde kullanılan yöntemler arasında Python tabanlı kütüphaneler ve yazılımlar öne çıkmaktadır. Bu tür analizlerde genellikle verilerin yapılandırılması ve işlenmesi için gelişmiş araçlar tercih edilir. Her ne kadar bilgiye erişim kolay olsa da, bu tür uygulamaların yasal ve etik boyutları hakkında bilgi sahibi olmak büyük önem taşımaktadır. Kısacası, internetten veri elde etme işlemleri dikkatli bir şekilde ele alındığında, her türlü araştırma ve analiz için değerli bilgiler sağlar.
Web Scraping Nedir ve Neden Kullanılır?
Web scraping, internet üzerindeki verilerin otomatik bir şekilde toplanmasını sağlayan bir tekniktir. Kullanıcılar, bu yöntemle belirli web sitelerinden veya sayfalardan istedikleri verileri hızlı bir şekilde çekebilirler. Veri işlemenin klasik yöntemlerine göre daha verimli ve hızlı bir alternatif sunar; böylece kullanıcılar zamanlarını daha verimli kullanabilirler. Bu tür bir veri çekme yöntemi, özellikle büyük veri analizi ve araştırmaları için hayati bir öneme sahiptir.
Web scraping, farklı alanlardan veri elde etmek için kullanılabilir. Örneğin, fiyat karşılaştırmaları yapmak, pazar araştırmaları gerçekleştirmek veya sosyal medya analizleri yapmak için bu teknikler oldukça faydalıdır. Kullanıcılar, web scraping ile verileri topladıktan sonra analiz edebilir ve önemli içgörüler elde edebilirler. Bu süreç, geleneksel veri toplama yöntemlerinin aksine, daha dinamik ve güncel verilerin elde edilmesine olanak tanır.
Beautiful Soup ile Web Verisi Çekme
Beautiful Soup, Python dilinde geliştirilmiş bir kütüphanedir ve HTML, XML gibi belgeleri ayrıştırmak için kullanılır. Kullanıcılar, sayfa kaynak kodundan ayrıştırma ağaçları oluşturarak belirli verileri kolayca çıkarabilirler. Geliştiriciler, bu güçlü araç sayesinde web sayfalarını parçalara ayırabilir ve istedikleri bilgilere ulaşmak için çok daha kolay bir yol izleyebilirler. Beautiful Soup, karmaşık yapılı verileri bile işlemek için yüksek düzeyde bir esneklik sunar.
Geliştirme sürecinde Beautiful Soup kullanmanın en büyük avantajlarından biri, kullanımının oldukça basit olmasıdır. Yeni başlayanlar bile bu kütüphaneyi hızlı bir şekilde öğrenebilirler. Dolayısıyla, Beautiful Soup, web scraping dünyasına adım atan pek çok kişi için ilk tercih olmuştur. Ayrıca, kullanıcı dostu yapısı sayesinde projelerde esneklik sağlar ve verilerin toplanması sürecini daha akıcı hale getirir.
Scrapy ile Verilerinizi Hızla Toplayın
Scrapy, yüksek düzeyde bir web scraping çerçevesidir ve Python ile geliştirilmiştir. Bu çerçeve, kullanıcıların verileri kolayca toplamasına ve düzenlemesine olanak tanır. Özellikle büyük ölçekli projeler için ideal bir çözüm sunar; çünkü Scrapy, çoklu sayfalardan veri çekmeyi destekler ve bu işlemi oldukça hızlı bir şekilde gerçekleştirir. Bunun yanı sıra, Scrapy’nin sunduğu çeşitli özellikler sayesinde, kullanıcılar isteğe bağlı olarak veri işleme süreçlerini özelleştirebilir.
Scrapy ile çalışmanın bir diğer avantajı, topladığınız verilerin düzenli bir yapı içerisinde saklanabilmesidir. Kullanıcılar, çeşitli formatlarda (JSON, CSV, XML vb.) çıktı alabilirler, bu da verilerin daha sonra analiz edilmesini kolaylaştırır. Scrapy, bu yönleriyle veri çekme yöntemlerinde oldukça popüler olmuştur. Veri mühendisleri ve analistleri, karmaşık yapılı internet sitelerinden bile verileri etkin bir şekilde toplayabilir.
Düzenli İfadelerle Hedef Verilerinizi Bulun
Düzenli ifadeler, web scraping süreçlerinde belirli bilgileri bulmak için kullanılan etkili bir araçtır. Genellikle, HTML belgelerinin karmaşık yapısını incelemek ve belirli veri kümelerini hızlı bir şekilde çıkarmak için diğer scraping araçlarıyla birleştirilir. Düzenli ifadeler, metin içindeki belirli desenleri tanımak ve yönetmek için mükemmel bir yöntemdir, bu yüzden web scraping uygulamalarında sıkça kullanılmaktadır.
Örneğin, bir HTML belgesinde belirli bir etiket içindeki tüm sayıları ya da e-posta adreslerini çekmek istediğinizde düzenli ifadeleri kullanabilirsiniz. Bu sayede, verileri toplarken zaman kazanırsınız ve analiz aşamasında daha az hata yapma ihtimaliniz olur. Sonuç olarak, düzenli ifadeler, web scraping teknik inşa etmek isteyenler için vazgeçilmez bir araçtır.
Web Scraping’de Etik Hususlar
Web scraping, her ne kadar güçlü bir araç olsa da, beraberinde bazı etik hususları da getirir. Öncelikle, scraping yapılacak web sitesinin ‘robots.txt’ dosyasını kontrol etmek önemlidir. Bu dosya, web sitesinin hangi bölümlerinin taranmasına izin verildiğini veya verilmediğini gösterir. Etik olarak, bu kurallara uymamak, web yöneticileriyle sorun yaşamanıza neden olabilir.
Ayrıca, bir sunucuyu aşırı yüklemekten kaçınılmalıdır. Çok sık yapılan veri talepleri, sunucu kaynaklarını tüketir ve bu da IP yasaklamalarına yol açabilir. Sorunların önüne geçmek için, isteklere bir zaman aralığı bırakmak ve web sitesinin kullanım şartlarına uymak gereklidir. Bu tür etik hususlara dikkat etmek, hem uzun vadede veri toplama sürecini hem de yasal sorunları minimize eder.
Web Scraping ile Büyük Veri Elde Etme
Web scraping, büyük veriyi toplamak için mükemmel bir yöntemdir. İnternet üzerinde milyonlarca web sitesi ve sayfa bulunmaktadır. Bu nedenle, bu sitelerden etkili bir şekilde veri toplayarak önünüzde geniş bir veri havuzu açılabilir. Veri çıkarma süreçlerini otomatikleştirmek, araştırmacılara daha derinlemesine analizler yapma imkânı tanır ve farklı sektörlerde yenilikçi çözümler üretmelerine yardımcı olur.
Büyük veri analitiği, günümüzde pek çok alanda önemli bir rol oynamaktadır. Şirketler, pazar araştırmaları, müşteri analizleri ve fiyat rekabeti gibi konularda veriye dayalı kararlar almak için web scraping yöntemlerini kullanıyorlar. Bu sayede, web scraping ile elde edilen büyük veriler, stratejik karar alma süreçlerine katkıda bulunarak rekabet avantajı yaratabilir.
Web Scraping Uygulama Alanları
Web scraping, farklı sektörlerde çeşitli uygulamaları olan bir tekniktir. E-ticaret siteleri, fiyat karşılaştırma platformları, sosyal medya analizleri ve veri toplama projeleri, bunların en dikkat çekici örneklerinden sadece birkaçıdır. Özellikle e-ticaret sektöründe, kullanıcılar, rakip fiyatlarını izlemek ve değerli içgörüler elde etmek amacıyla web scraping yöntemlerinden yararlanmaktadır.
Ayrıca, sosyal medya siteleri üzerinde yapılan analizler ile kullanıcı davranışları hakkında bilgi edinilebilir. Markalar, bu verileri pazarlama stratejilerini geliştirmek ve hedef kitleleriyle daha etkili bir şekilde etkileşim kurmak için kullanabilmektedir. Web scraping, yenilikçi yaklaşımlar sayesinde, gereksinimlere uygun çözümler üreterek hızla gelişen bir alan haline gelmiştir.
Web Scraping’de Karşılaşılan Zorluklar
Web scraping, faydalı bir araç olmasının yanı sıra bazı zorluklarla da karşılaşılabilir. Çoğu web sitesi, botlardan korunmak için çeşitli güvenlik önlemleri alır. Bu tür önlemler, scraping yapan kullanıcıları zor durumda bırakabilir. Çerezler, CAPTCHA istekleri ve IP engellemeleri gibi engeller, veri alma işlemlerini zorlaştırabilir.
Bu nedenle, etkili bir web scraping stratejisi geliştirmek için bu zorlukların üstesinden gelinmesi gereklidir. Farklı scraping araçları ve teknikleri kullanarak bu durumların üstesinden gelebilir ve başarılı veri toplama süreçleri gerçekleştirebilirsiniz. Kullanıcıların bu zorluklarla başa çıkabilmek için adapte olmaları ve yenilikçi çözümler bulmaları gerekmektedir.
Yasal Düzenlemeler ve Web Scraping
Web scraping uygulamalarının yasal durumu ve düzenlemeleri, kullanıcıların dikkat etmesi gereken önemli bir konudur. Her ülkenin kendi veri koruma yasaları ve web scraping ile ilgili yasal çerçeveleri bulunmaktadır. Kullanıcılar, scraping faaliyetlerini gerçekleştirmeden önce, bu yasal düzenlemelere hakim olmalı ve hangi kısıtlamalara tabi olduklarını bilmelidirler.
Ayrıca, veri toplama süreçlerinde etik kurallara uymak önemlidir. Yanlış anlaşılmalar ve hukuki sorunlardan kaçınmak için, web sitelerinin kullanım şartlarına riayet edilmesi büyük önem taşımaktadır. Bu nedenle, web scraping yaparken yasal süreçleri göz önünde bulundurmak, sorunsuz bir deneyim yaşamanıza yardımcı olabilir.
Sıkça Sorulan Sorular
Web scraping teknikleri nelerdir?
Web scraping teknikleri, kullanıcıların veri çekme yöntemlerini çeşitlendirmelerine olanak tanır. En yaygın yöntemlerden bazıları Beautiful Soup ve Scrapy gibi Python kütüphaneleri kullanmaktır. Beautiful Soup, HTML ve XML belgelerini ayrıştırmak için idealken, Scrapy kullanıcıların web sitelerinden hızlı ve yapılandırılmış verileri çıkarmasına yardımcı olur.
Beautiful Soup nedir ve nasıl kullanılır?
Beautiful Soup, Python programlama dilinde HTML ve XML belgelerini kolayca ayrıştırmak için kullanılan bir kütüphanedir. Web scraping uygulamalarında, web sayfalarının kaynağından veri çekme işlemi için ayrıştırma ağaçları oluşturarak kullanıcıların ihtiyaç duyduğu bilgileri hızlıca bulma imkânı sunar.
Scrapy ile veri çekme yöntemleri nasıl çalışıyor?
Scrapy, web scraping için geliştirilmiş yüksek seviyeli bir çerçevedir. Web sitelerini tarama yeteneği sayesinde, kullanıcıların belirledikleri URL’lerden veri çekmelerine imkân tanır. Scrapy ile birlikte, sayfaları takip edebilir, formları doldurabilir ve yapılandırılmış veriyi kolaylıkla çıkarabilirsiniz.
Web scraping sırasında dikkat edilmesi gereken etik hususlar nelerdir?
Web scraping sırasında etik hususlar büyük bir önem taşır. İlk olarak, web sitelerinin ‘robots.txt’ dosyası kontrol edilmelidir. Bu dosya, hangi alanların taranıp taranamaması gerektiğine dair bilgiler içerir. Ayrıca, sunucuları aşırı yüklemekten kaçınmak, yasal sorunların önüne geçmek için kritik bir kuraldır.
Web scraping’in yasal durumu hakkında ne biliyoruz?
Web scraping’in yasal durumu, ülkeden ülkeye değişiklik gösterir. Genel kural olarak, web sitelerinin hizmet şartları ve ‘robots.txt’ dosyasının kontrol edilmesi önerilir. İzin almadan veri çekme işlemleri, telif hakkı ihlalleri ve yasal sorunlara yol açabilir.
| Teknik | Açıklama | |
|---|---|---|
| Beautiful Soup | HTML ve XML belgelerini ayrıştırmak için kullanılan Python kütüphanesidir. | |
| Scrapy | Web sitelerini taramak için yüksek seviyeli bir Python çerçevesidir. | |
| Düzenli İfadeler | HTML belgelerinden bilgi bulmak için diğer araçlarla birleştirilebilir. | |
| Etik Hususlar | Web scraping’in yasal durumu hakkında bilgi sahibi olmak önemlidir. | |
Özet
Web scraping, veri toplamak için etkili bir yöntemdir. Bu süreçte, Beautiful Soup ve Scrapy gibi kütüphanelerin kullanımı, kullanıcıların verileri kolayca çekmelerini sağlar. Ancak, web scraping yaparken etik ve yasal kurallara dikkat etmek hayati önem taşır. Dolayısıyla, scraping işlemlerini gerçekleştirirken her zaman sitenin ‘robots.txt’ dosyasını kontrol etmek ve aşırı yüklemelerden kaçınmak gerekmektedir. Bu şekilde, verimli ve güvenilir bir şekilde web scraping yapabiliriz.